Publications
2025
-
 The Oversmoothing Fallacy: A Misguided Narrative in GNN ResearchMoonJeong Park, Sunghyun Choi, Jaeseung Heo, Eunhyeok Park, and Dongwoo Kim2025
The Oversmoothing Fallacy: A Misguided Narrative in GNN ResearchMoonJeong Park, Sunghyun Choi, Jaeseung Heo, Eunhyeok Park, and Dongwoo Kim2025Oversmoothing has been recognized as a main obstacle to building deep Graph Neural Networks (GNNs), limiting the performance. This position paper argues that the influence of oversmoothing has been overstated and advocates for a further exploration of deep GNN architectures. Given the three core operations of GNNs, aggregation, linear transformation, and non-linear activation, we show that prior studies have mistakenly confused oversmoothing with the vanishing gradient, caused by transformation and activation rather than aggregation. Our finding challenges prior beliefs about oversmoothing being unique to GNNs. Furthermore, we demonstrate that classical solutions such as skip connections and normalization enable the successful stacking of deep GNN layers without performance degradation. Our results clarify misconceptions about oversmoothing and shed new light on the potential of deep GNNs.
-
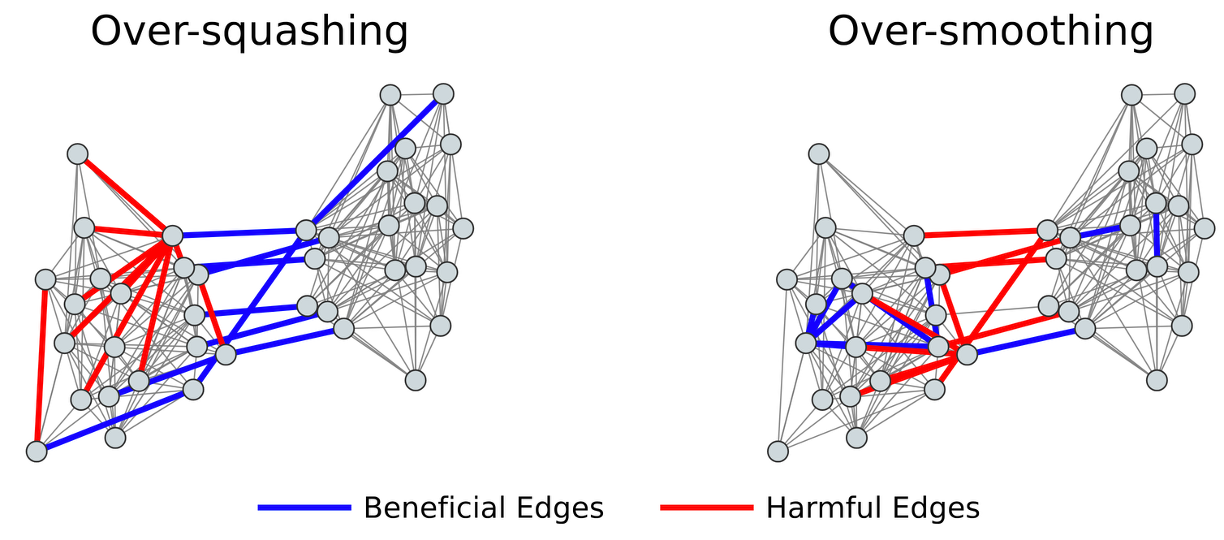 Influence Functions for Edge Edits in Non-Convex Graph Neural NetworksJaeseung Heo, Kyeongheung Yun, Seokwon Yoon, MoonJeong Park, Jungseul Ok, and Dongwoo Kim2025
Influence Functions for Edge Edits in Non-Convex Graph Neural NetworksJaeseung Heo, Kyeongheung Yun, Seokwon Yoon, MoonJeong Park, Jungseul Ok, and Dongwoo Kim2025Understanding how individual edges influence the behavior of graph neural networks (GNNs) is essential for improving their interpretability and robustness. Graph influence functions have emerged as promising tools to efficiently estimate the effects of edge deletions without retraining. However, existing influence prediction methods rely on strict convexity assumptions, exclusively consider the influence of edge deletions while disregarding edge insertions, and fail to capture changes in message propagation caused by these modifications. In this work, we propose a proximal Bregman response function specifically tailored for GNNs, relaxing the convexity requirement and enabling accurate influence prediction for standard neural network architectures. Furthermore, our method explicitly accounts for message propagation effects and extends influence prediction to both edge deletions and insertions in a principled way. Experiments with real-world datasets demonstrate accurate influence predictions for different characteristics of GNNs. We further demonstrate that the influence function is versatile in applications such as graph rewiring and adversarial attacks.
-
 CoPL: Collaborative Preference Learning for Personalizing LLMsYoungbin Choi, Seunghyuk Cho, Minjong Lee, MoonJeong Park, Yesong Ko, Jungseul Ok, and Dongwoo Kim2025
CoPL: Collaborative Preference Learning for Personalizing LLMsYoungbin Choi, Seunghyuk Cho, Minjong Lee, MoonJeong Park, Yesong Ko, Jungseul Ok, and Dongwoo Kim2025Personalizing large language models (LLMs) is important for aligning outputs with diverse user preferences, yet existing methods struggle with flexibility and generalization. We propose CoPL (Collaborative Preference Learning), a graph-based collaborative filtering framework that models user-response relationships to enhance preference estimation, particularly in sparse annotation settings. By integrating a mixture of LoRA experts, CoPL efficiently fine-tunes LLMs while dynamically balancing shared and user-specific preferences. Additionally, an optimization-free adaptation strategy enables generalization to unseen users without fine-tuning. Experiments on UltraFeedback-P demonstrate that CoPL outperforms existing personalized reward models, effectively capturing both common and controversial preferences, making it a scalable solution for personalized LLM alignment.



2024
-
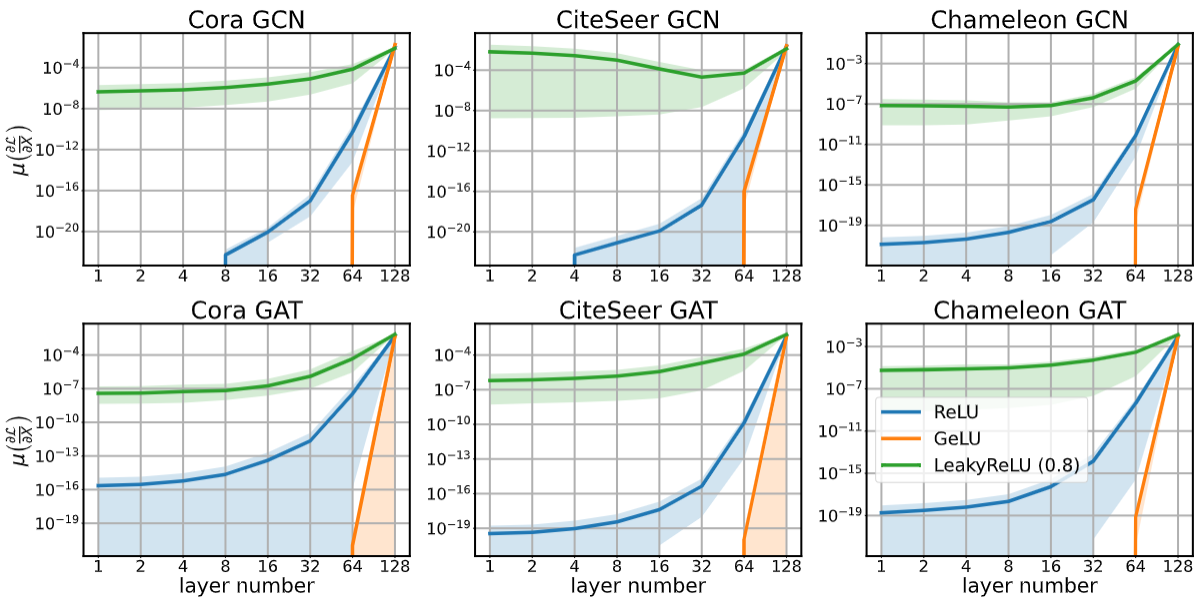 Taming Gradient Oversmoothing and Expansion in Graph Neural NetworksMoonJeong Park, and Dongwoo Kim2024
Taming Gradient Oversmoothing and Expansion in Graph Neural NetworksMoonJeong Park, and Dongwoo Kim2024Oversmoothing has been claimed as a primary bottleneck for multi-layered graph neural networks (GNNs). Multiple analyses have examined how and why oversmoothing occurs. However, none of the prior work addressed how optimization is performed under the oversmoothing regime. In this work, we show the presence of \textitgradient oversmoothing preventing optimization during training. We further analyze that GNNs with residual connections, a well-known solution to help gradient flow in deep architecture, introduce \textitgradient expansion, a phenomenon of the gradient explosion in diverse directions. Therefore, adding residual connections cannot be a solution for making a GNN deep. Our analysis reveals that constraining the Lipschitz bound of each layer can neutralize the gradient expansion. To this end, we provide a simple yet effective normalization method to prevent the gradient expansion. An empirical study shows that the residual GNNs with hundreds of layers can be efficiently trained with the proposed normalization without compromising performance. Additional studies show that the empirical observations corroborate our theoretical analysis.
-
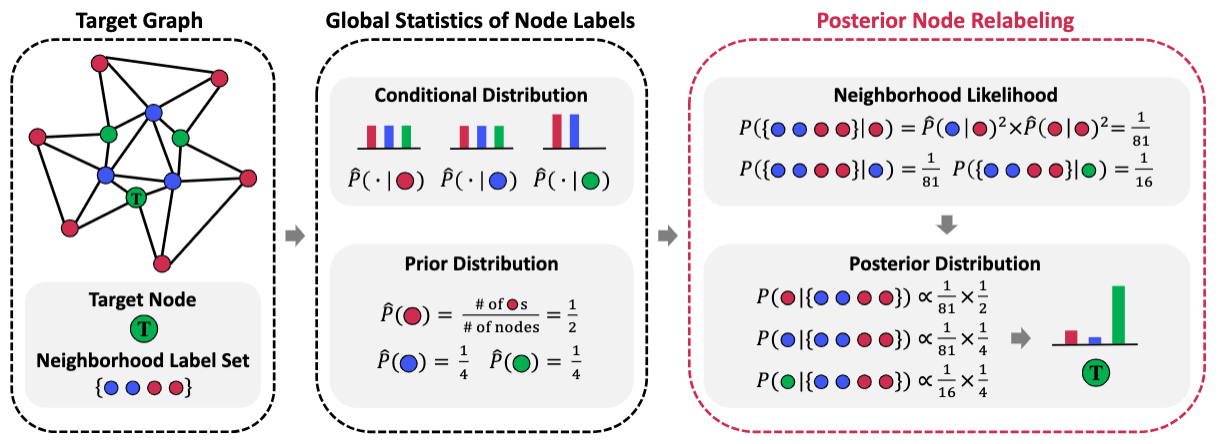 Posterior Label Smoothing for Node ClassificationJaeseung Heo, MoonJeong Park, and Dongwoo Kim2024
Posterior Label Smoothing for Node ClassificationJaeseung Heo, MoonJeong Park, and Dongwoo Kim2024Soft labels can improve the generalization of a neural network classifier in many domains, such as image classification. Despite its success, the current literature has overlooked the efficiency of label smoothing in node classification with graph-structured data. In this work, we propose a simple yet effective label smoothing for the transductive node classification task. We design the soft label to encapsulate the local context of the target node through the neighborhood label distribution. We apply the smoothing method for seven baseline models to show its effectiveness. The label smoothing methods improve the classification accuracy in 10 node classification datasets in most cases. In the following analysis, we find that incorporating global label statistics in posterior computation is the key to the success of label smoothing. Further investigation reveals that the soft labels mitigate overfitting during training, leading to better generalization performance.
-
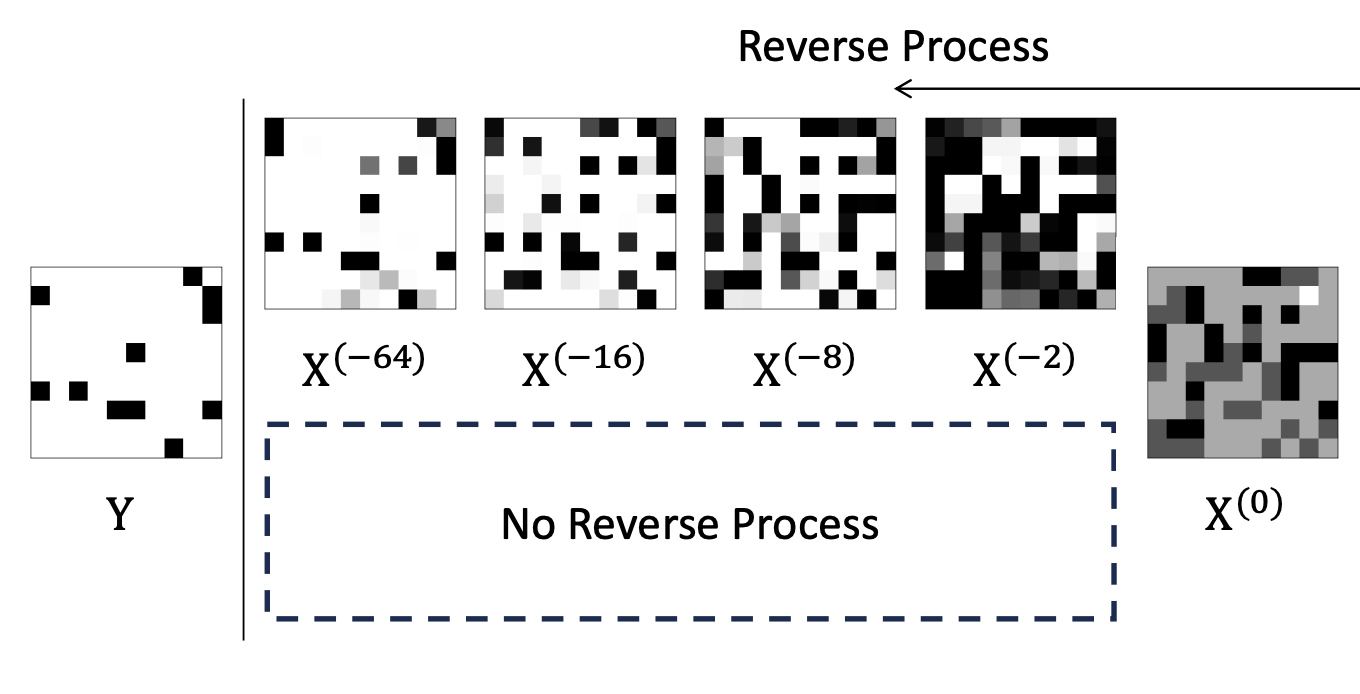 Mitigating Oversmoothing Through Reverse Process of GNNs for Heterophilic GraphsMoonJeong Park, Jaeseung Heo, and Dongwoo KimInternational Conference on Machine Learning (ICML), 2024Excellent Paper Award at BK21 Paper Award
Mitigating Oversmoothing Through Reverse Process of GNNs for Heterophilic GraphsMoonJeong Park, Jaeseung Heo, and Dongwoo KimInternational Conference on Machine Learning (ICML), 2024Excellent Paper Award at BK21 Paper AwardGraph Neural Network (GNN) resembles the diffusion process, leading to the over-smoothing of learned representations when stacking many layers. Hence, the reverse process of message passing can produce the distinguishable node representations by inverting the forward message propagation. The distinguishable representations can help us to better classify neighboring nodes with different labels, such as in heterophilic graphs. In this work, we apply the design principle of the reverse process to the three variants of the GNNs. Through the experiments on heterophilic graph data, where adjacent nodes need to have different representations for successful classification, we show that the reverse process significantly improves the prediction performance in many cases. Additional analysis reveals that the reverse mechanism can mitigate the over-smoothing over hundreds of layers. Our code is available at https://github.com/ml-postech/reverse-gnn.



2023
-
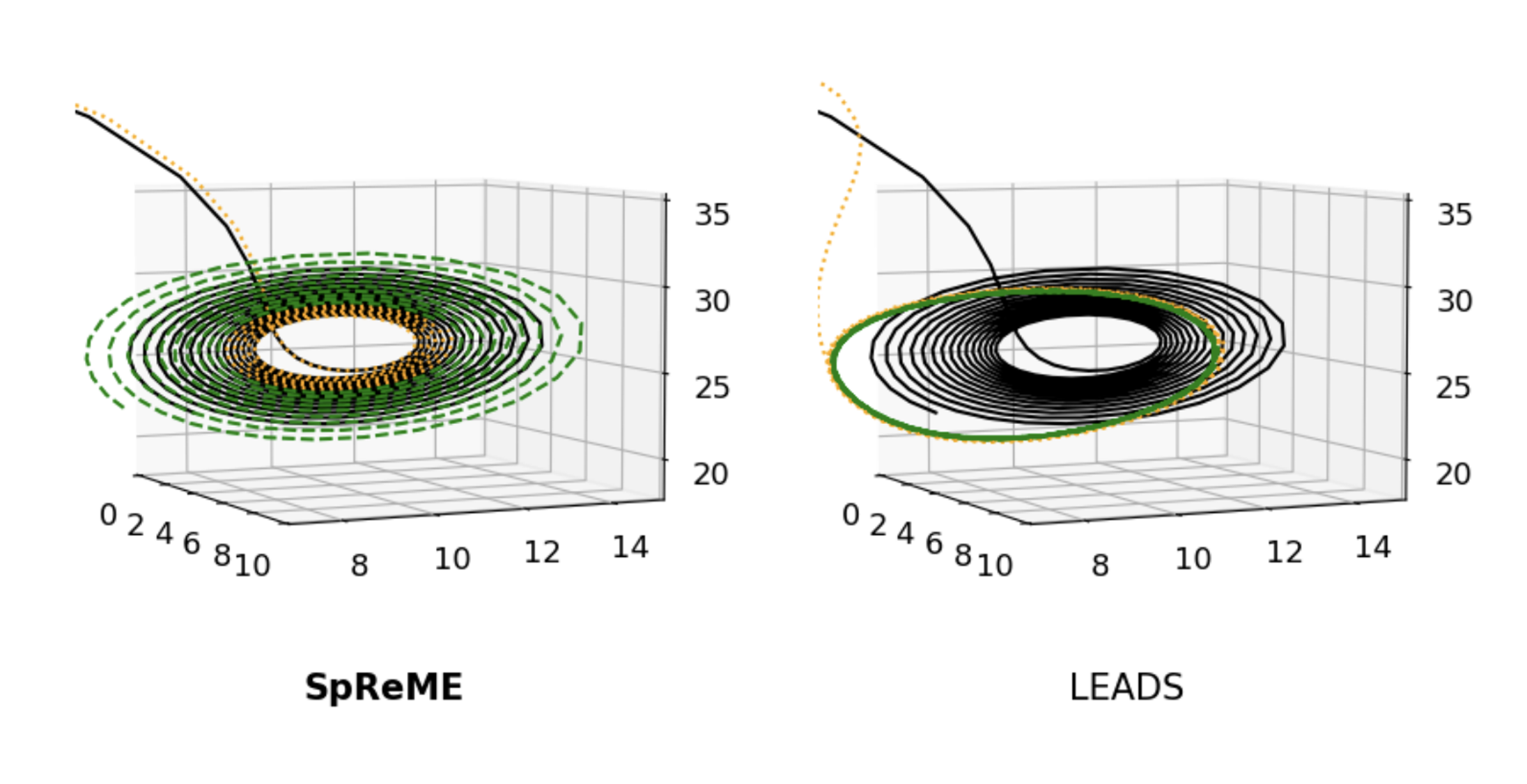 SpReME: Sparse Regression for Multi-Environment Dynamic Systems,MoonJeong Park*, Youngbin Choi*, and Dongwoo KimAAAI Conference on Artificial Intelligence, Workshop on When Machine Learning meets Dynamical Systems: Theory and Applications (AAAIw), 2023
SpReME: Sparse Regression for Multi-Environment Dynamic Systems,MoonJeong Park*, Youngbin Choi*, and Dongwoo KimAAAI Conference on Artificial Intelligence, Workshop on When Machine Learning meets Dynamical Systems: Theory and Applications (AAAIw), 2023This paper introduces a new weakly supervised learning approach for instance segmentation using extreme points, i.e., the topmost, leftmost, bottommost, and rightmost points of an object. Although these points are readily available in the modern bounding box annotation process and offer strong clues for precise segmentation, they have received less attention in the literature. Motivated by this, our study explores extreme point supervised instance segmentation to further enhance performance at the same annotation cost with box-supervised methods. Our work considers extreme points as a part of the true instance mask and propagates them to identify potential foreground and background points, which are all together used for training a pseudo label generator. Then pseudo labels given by the generator are in turn used for supervised learning of our final model. Our model generates high-quality masks, particularly when the target object is separated into multiple parts, where previous box-supervised methods often fail. On three public benchmarks, our method significantly outperforms existing box-supervised methods, further narrowing the gap with its fully supervised counterpart.

2022
-
 MetaSSD: Meta-Learned Self-Supervised Detection,MoonJeong Park, Jungseul Ok, Yo-Seb Jeon, and Dongwoo KimIEEE International Symposium on Information Theory (ISIT), 2022
MetaSSD: Meta-Learned Self-Supervised Detection,MoonJeong Park, Jungseul Ok, Yo-Seb Jeon, and Dongwoo KimIEEE International Symposium on Information Theory (ISIT), 2022Deep learning-based symbol detector gains increasing attention due to the simple algorithm design than the traditional model-based algorithms such as Viterbi and BCJR. The supervised learning framework is often employed to train a model, where true symbols are necessary. There are two major limitations in the supervised approaches: a) a model needs to be retrained from scratch when new train symbols come to adapt to a new channel status, and b) the length of the training symbols needs to be longer than a certain threshold to make the model generalize well on unseen symbols. To overcome these challenges, we propose a meta-learning-based self-supervised symbol detector named MetaSSD. Our contribution is two-fold: a) meta-learning helps the model adapt to a new channel environment based on experience with various meta-training environments, and b) self-supervised learning helps the model to use relatively less supervision than the previously suggested learning-based detectors. In experiments, MetaSSD outperforms OFDM-MMSE with noisy channel information and shows comparable results with BCJR. Further ablation studies show the necessity of each component in our framework.
-
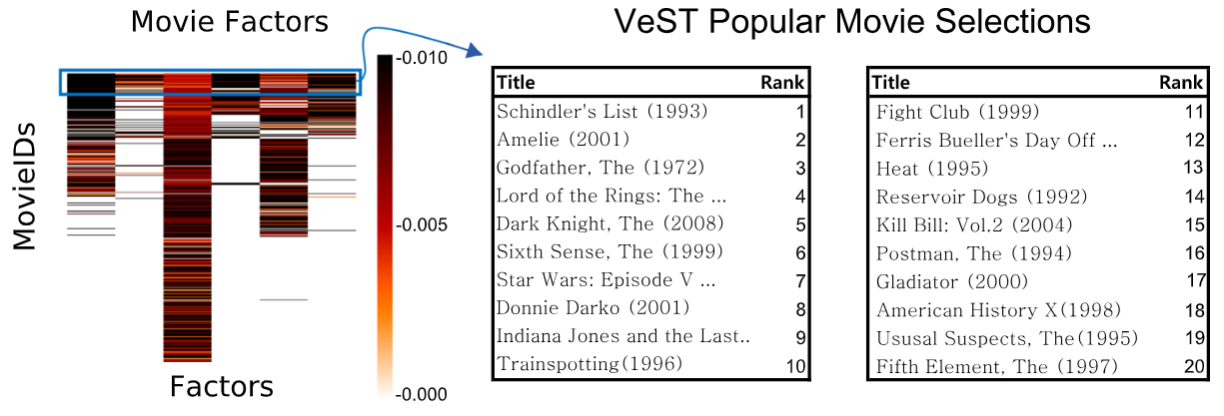 Large-scale tucker Tensor factorization for sparse and accurate decomposition,Jun-Gi Jang*, MoonJeong Park*, Jongwuk Lee, and Lee SaelThe Journal of Supercomputing, 2022Extended version of the conference paper "VeST: Very Sparse Tucker Factorization of Large-Scale Tensors"
Large-scale tucker Tensor factorization for sparse and accurate decomposition,Jun-Gi Jang*, MoonJeong Park*, Jongwuk Lee, and Lee SaelThe Journal of Supercomputing, 2022Extended version of the conference paper "VeST: Very Sparse Tucker Factorization of Large-Scale Tensors"How can we generate sparse tensor decomposition results for better interpretability? Typical tensor decomposition results are dense. Dense results require additional postprocessing for data interpretation, especially when the data are large. Thus, we present a large-scale Tucker factorization method for sparse and accurate tensor decomposition, which we call the Very Sparse Tucker factorization (VeST) method. The proposed VeST outputs highly sparse decomposition results from a large-scale partially observable tensor data. The approach starts by decomposing the input tensor data, then iteratively determining unimportant elements, removing them, and updating the remaining elements until a terminal state is reached. We define ‘responsibility’ of each element on the reconstruction error to determine unimportant elements in the decomposition results. The decomposition results are updated iteratively in parallel using carefully constructed coordinate descent rules for scalable computation. Furthermore, the suggested method automatically looks for the optimal sparsity ratio, resulting in a balanced sparsity-accuracy trade-off. Extensive experiments using real-world datasets showed that our method produces more accurate results than that of the competitors. Experiments further showed that the proposed method is scalable in terms of the input dimensionality, the number of observable entries, and the thread count.


2021
-
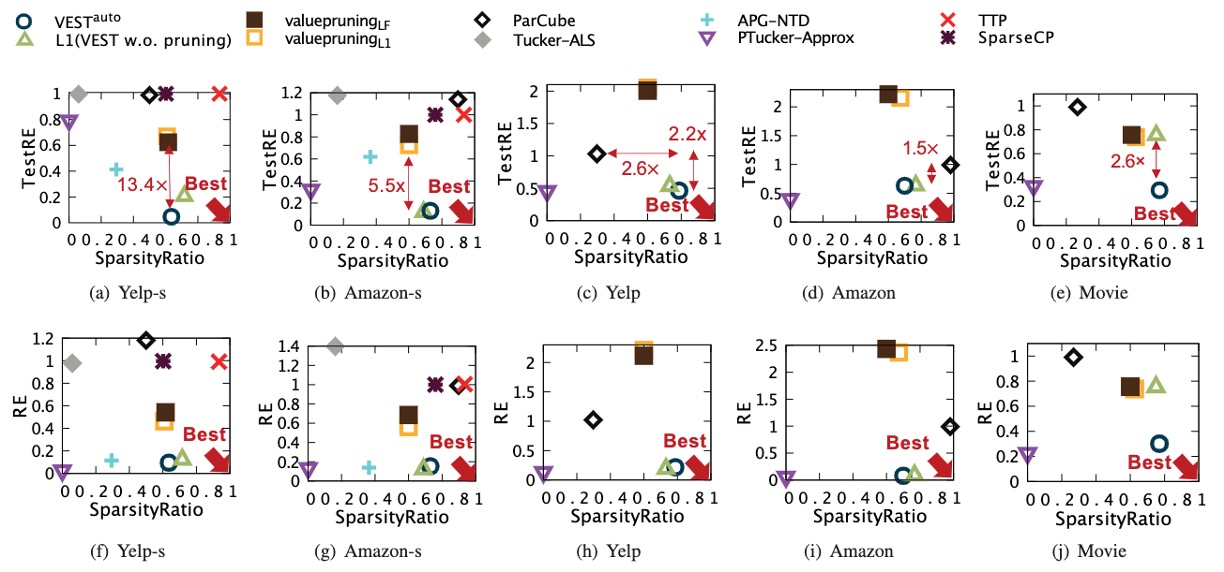 VeST: Very Sparse Tucker Factorization of Large-Scale Tensors,MoonJeong Park*, Jun-Gi Jang*, and Lee SaelIEEE International Conference on Big Data and Smart Computing (BigComp), 2021Best Paper Award, 1st Place
VeST: Very Sparse Tucker Factorization of Large-Scale Tensors,MoonJeong Park*, Jun-Gi Jang*, and Lee SaelIEEE International Conference on Big Data and Smart Computing (BigComp), 2021Best Paper Award, 1st PlaceGiven a large tensor, how can we decompose it to sparse core tensor and factor matrices without reducing the accuracy? Existing approaches either output dense results or have scalability issues. In this paper, we propose VEST, a tensor factorization method for large partially observable data to output a very sparse core tensor and factor matrices. VEST performs initial decomposition and iteratively determines unimportant entries in the decomposition results, removes the unimportant entries, and updates the remaining entries. To determine unimportant entries of factor matrices and core tensor, we define and use the entry-wise ‘responsibility’ of the current decomposition. For scalable computation, the entries are updated iteratively using a carefully derived coordinate descent rule in parallel. Also, VEST automatically searches for the best sparsity ratio that results in a balanced trade-off between sparsity and accuracy. Extensive experiments show that our method VEST produces more accurate results compared to the best performing competitors for all tested real-life datasets.
